
Some Citation Parsing Statistics
We want to share some quick statistics today. We we just completed running our citation parser across the entire CourtListener collection. If you follow our work, you'll know that the purpose of the citation parser is to go through every opinion in CourtListener and identify every citation from one opinion to another (such as "410 U.S. 113"). Once identified, the parser looks up the citation and attempts to make a hyperlink between the opinions so that if you see a citation while reading, you can click it to go to the correct place.
As you can imagine, looking up every citation in every opinion in CourtListener can take some time, so we only run our citation finder when we need to. In this case:
- The process ran continuously for two weeks.
- It ran a total of 253,872,460 queries against our search engine.
- It found 25,471,410 citations between opinions.
- There are about three million opinions currently in CourtListener.
After running the parser, the first stop I like to take is to go and see the search results ordered by citation count. In an upset, Strickland v. Washington, the former leader, has been pushed to third place by Anderson v. Libby Lobby and by Celotex v. Catrell:
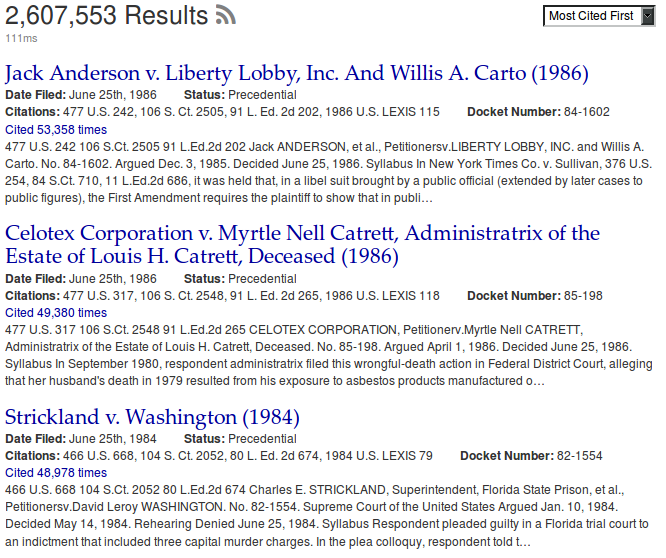
The Most Cited Opinions in CourtListener
Since the citations also impact the relevance engine, I also like to see which cases are considered the most relevant when no query is made. In this case, the top five are:
- With 34,260 cites, Anders v. California
- With 1,589 cites, Boyd v. United States
- With 1,548 cites, Weeks v. United States
- With 28,212 cites, Miranda v. Arizona
- With 48,998 cites, Strickland v. Washington
If you're wondering why the most cited cases are not the most relevant cases, the answer is that relevance is a combination of both what cites a case and how many times it is cited. For example, if a case is cited many times by cases that in turn are never cited, that case might not be as relevant as one that is cited a few times by other cases that are very popular. If this sounds confusing, that's because it's a recursive technique. The relevance of every item affects every item. The more a case is cited by cases that are cited by many cases that are cited by many cases that are cited by many cases…and so on…the more relevant it is.
Running the citation parser requires our servers to do a lot of work, so we only run it when we need to. This time we needed to run it as part of the major upgrade we just finished so that the database and search engine were updated properly.
As always, we're proud to offer these citations as a CSV in our bulk data or via the CourtListener API.
