
Open Source Tools
We encourage members of the legal technology ecosystem to use our robust set of open source tools for legal data and research needs.
For more than a decade we have created open source libraries so that our work benefit others. We hope you'll join us in this collaborative effort to build foundational tools to help organizations innovate and researchers thrive.
All libraries on this page are licensed under the BSD 2-Clause license.
Juriscraper: Legal Scraping Toolkit
Juriscraper is a data gathering library written in Python that collects legal opinions, PACER content, and oral arguments from the American court system.
Juriscraper is currently able to scrape:
-
Opinions from all major appellate Federal courts
-
Opinions from all state courts of last resort (typically their "Supreme Court")
-
Oral arguments from all appellate federal courts that offer them
-
A variety of content from PACER
Jursicraper has a robust test suite, and it underpins much of the functionality of the CourtListener system. It's no exaggeration to say that Juriscraper has scraped tens of millions of court records.
Juriscraper aims to be a unified scraper framework that organizations can use to get the latest content from American courts. We hope this tool will be an asset to your scraping work and that you'll join us in using it.
Eyecite: Citation Extractor
Eyecite is a high performance, robust, open source tool for extracting legal citations from text.
It has been tested against more than fifty million citations, and is used, among other things, to annotate millions of legal documents in the collections of CourtListener and the Caselaw Access Project.
Eyecite was developed in collaboration with the Harvard Library Innovation Lab.
Eyecite recognizes a wide variety of citations commonly appearing in American legal decisions, including:
| Type | Example |
|---|---|
| Full | Bush v. Gore, 531 U.S. 98, 99-100 (2000) |
| Short | 531 U.S., at 99 |
| Statutory | Mass. Gen. Laws ch. 1, § 2 |
| Law Journal | 1 Minn. L. Rev. 1 |
| Supra | Bush, supra, at 100 |
| id | Id., at 101 |
Eyecite is powered by our database of reporters, which has information about nearly every reporter in American history.
To learn more about eyecite, read the whitepaper describing its features in detail or check it out on Github.
X-Ray: Bad Redaction Detector
X-Ray is a fast and robust tool to identify bad redactions in PDF files.
An ongoing problem we encounter as we gather court data is that people routinely fail to properly redact documents. Instead of doing it the right way, people draw a black rectangle or a black highlight on top of black text.
When this happens it is trivial to reveal the badly redacted text under the rectangle. To do so, you simply select the text that remains in the document and copy/paste it somewhere else.
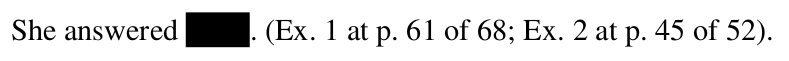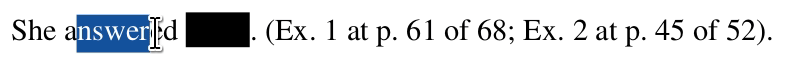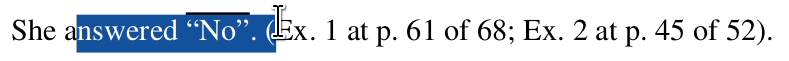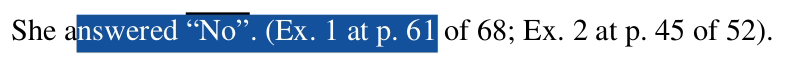
In light of this problem, X-Ray serves two goals:
-
We have run X-Ray across millions of PDFs in our system and are using the results of that research to educate the public about the prevalence of this problem.
-
By releasing this tool as a well-maintained open source utility, we are making it as easy as possible for law firms, courts, and others to get ahead of this problem, before yet another badly-redacted document is made public.
At present, X-Ray supports only the most basic (and most common) type of bad redaction, rectangles on top of text. There are a variety of other types of bad redaction though, and we hope to add additional features as this tool gains more usage.
We have built X-Ray to be fast — so it can process millions of PDFs — and we have used a full test suite to make sure it will only get better over time.
Doctor: Document Conversion at Scale
Doctor is a microservice for converting and extracting documents and audio files.
As a part of building CourtListener, we have spent years optimizing our document extraction and audio conversion pipelines. Doctor is the culmination of this work and has functionality like:
- Extracting text from documents, including WPD, PDF, DOC, DOCX, RTF, and more.
- Completing optimized OCR extraction on image-based PDFs.
- Getting page counts from different document types.
- Converting audio files from WMA, OGG, WAV, and others to MP3.
- Making a PDF from images.
- Creating thumbnails from PDFs.
Doctor is designed to scale while providing performant high-quality results. It can be scaled horizontally via a multi-worker or orchestrated single-worker model.
The code in Doctor has processed tens of millions of documents and over 2.5 million minutes of audio.
We hope you will try Doctor in your project and that it can be a powerful tool for your work.
Inception: Embedding Generator
Inception is a high-performance microservice to seamlessly generate embeddings for legal documents and queries.
This tool is entirely open-source, allowing you to use it out of the box or integrate it into your own applications. It is a FastAPI service that generates text embeddings using SentenceTransformers, specifically designed for processing legal documents and search queries. The service efficiently handles both short search queries and lengthy court opinions, generating semantic embeddings that can be used for document similarity matching and semantic search applications. It includes support for GPU acceleration when available.
